TOON: a new way to structure data for language models
Token Oriented Object Notation is a compact, human-readable format for feeding structured data into LLMs. It's not a JSON replacement, but for the right shapes, it earns its place.
CMO take: TOON is a compact, human-readable data format designed for feeding structured data into large language models. On published benchmarks it achieves higher accuracy than JSON while using fewer tokens overall on the tested datasets. I use JSON extensively across my workflows and will continue to. I am testing TOON for cases where the input is large, has a consistent structure, and is close to context limits. TOON is not a replacement for JSON or CSV. It is a format to evaluate for specific structured workloads.
GitHub repo: github.com/toon-format/toon
Token Oriented Object Notation (TOON) is a new serialisation format that AI professionals are starting to talk about. It is designed for one job: pass structured data into language models with less token waste, while preserving the full information that would normally be represented in JSON.
The TOON authors describe it as a lossless, drop-in representation of JSON for LLM input. You keep JSON in your systems and storage. When you need to send data into a model, you convert JSON to TOON at the boundary.
I spend a lot of time testing how different formats and prompt schemes affect accuracy, cost, and context usage. JSON is still the primary format I use because it is predictable and works everywhere. TOON is new. This note is a status update: what it is, where it works, where it does not, and what the published benchmarks actually show.
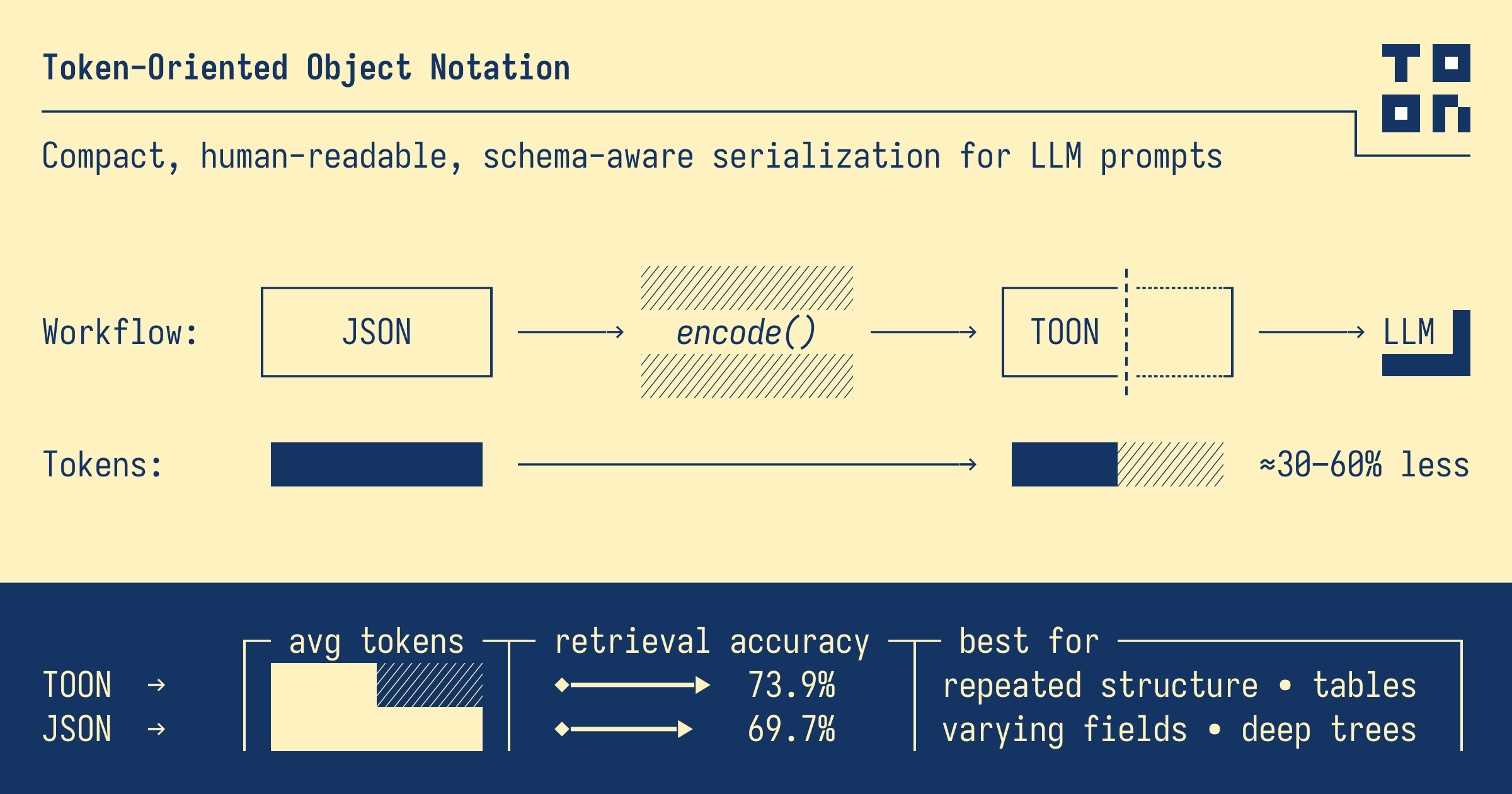
What TOON is
TOON is a compact, human-readable serialisation format designed specifically for LLM input. It has three main design ideas:
- It targets the same data as JSON. It is intended as a lossless representation of JSON data for LLMs. If you can encode it as JSON, you can encode it as TOON.
- It focuses on uniform arrays of objects. Its sweet spot is arrays where every item has the same fields, for example campaign rows, product rows, event rows. In those cases JSON repeats the same keys for every item. TOON declares the fields once and streams the data as rows.
- It combines ideas from YAML and CSV. Indentation-based structure for nested objects, similar to YAML. Tabular blocks for uniform arrays, similar to CSV. Syntax stripped down to what the model needs: fewer braces, brackets, and quotes.
The key claim is that this structure is both token-efficient and easier for models to interpret reliably.
Example: JSON vs TOON
The TOON documentation uses a simple example with users. Here’s a marketing-style version: channel performance.
JSON
{
"campaign_performance": [
{ "channel": "Search", "impressions": 185000, "clicks": 5200, "conversions": 310 },
{ "channel": "Social", "impressions": 94000, "clicks": 2100, "conversions": 120 },
{ "channel": "Display", "impressions": 72000, "clicks": 1300, "conversions": 45 }
]
}TOON
campaign_performance[3]{channel,impressions,clicks,conversions}:
Search,185000,5200,310
Social,94000,2100,120
Display,72000,1300,45Same information. TOON declares the row structure once, then streams the data. For large arrays this pattern is where the token savings accumulate.
Key features (from the spec)
The TOON documentation highlights several properties:
- Token efficient: typically 30 to 60 percent fewer tokens on large uniform arrays compared to formatted JSON.
- LLM-friendly guardrails: explicit array lengths and field lists help with validation and error checking.
- Minimal syntax: removes redundant punctuation such as braces, most quotes, and repeated keys.
- Indentation-based nesting: uses whitespace for structure instead of braces.
- Tabular arrays: arrays of uniform objects are encoded as rows with a single header.
- Optional key folding: can collapse simple nested key chains into dotted paths to reduce indentation and tokens, e.g.
data.metadata.items.
Importantly, TOON is described as production-ready but also an idea in progress. The spec invites feedback and contributions.
When not to use TOON
The GitHub documentation is explicit about TOON’s limitations. It is not always the best format.
TOON excels with uniform arrays of objects, but other formats are better in several cases:
- Deeply nested or non-uniform structures (tabular eligibility ≈ 0 percent). When there is no usable tabular pattern, JSON compact often uses fewer tokens.
- Semi-uniform arrays (about 40 to 60 percent tabular). Arrays where some fields repeat but many are optional or inconsistent. Token savings decline in this range. If your pipeline is already built around JSON, the documentation suggests staying with JSON unless you have a strong reason to change.
- Pure tabular data. For flat tables, CSV is smaller than TOON. TOON adds about 5 to 10 percent overhead to include explicit structure such as array lengths, field headers, and delimiter scoping. The tradeoff is size versus stronger guardrails for LLMs.
- Latency-critical applications. If end-to-end latency is your main constraint, the authors recommend benchmarking on your actual setup. Some deployments, especially local or quantised models such as those run via Ollama, may process compact JSON faster even if TOON uses fewer tokens.
These caveats are important. TOON is optimised for a particular set of shapes. Outside those shapes, JSON compact or CSV may be a better fit.
Benchmarks: what the data shows
The TOON repository includes a benchmark suite that measures retrieval accuracy and token usage across 209 data retrieval questions on four different models. The tests are split into two tracks.
- Mixed structure track, datasets with nested or semi-uniform structures. TOON vs JSON, JSON compact, YAML, XML. CSV excluded because it cannot represent nested structures.
- Flat only track, datasets with flat tabular structures, where CSV is valid. CSV vs TOON vs JSON, JSON compact, YAML, XML.
Overall efficiency ranking
The main summary metric is accuracy per 1,000 tokens across the full benchmark suite:
| Format | Score | Accuracy | Tokens |
|---|---|---|---|
| TOON | 26.9 | 73.9% | 2,744 |
| JSON compact | 22.9 | 70.7% | 3,081 |
| YAML | 18.6 | 69.0% | 3,719 |
| JSON | 15.3 | 69.7% | 4,545 |
| XML | 13.0 | 67.1% | 5,167 |
Key fact from the documentation: TOON achieves 73.9 percent accuracy compared to JSON at 69.7 percent, while using 39.6 percent fewer tokens on these datasets.
CSV is left out of this ranking because it can only handle 109 of the 209 questions, since it cannot represent nested structures. For the flat-only track, CSV is more token-efficient than TOON but cannot cover the mixed track.
Per-model accuracy
The per-model results also show TOON at or near the top.
Claude Haiku 4.5: TOON 59.8% / JSON 57.4% / YAML 56.0% / XML 55.5% / JSON compact 55.0% / CSV 50.5% (subset).
Gemini 2.5 Flash: TOON 87.6% / JSON compact 82.3% / YAML 79.4% / XML 79.4% / JSON 77.0% / CSV 86.2% (flat).
GPT-5 nano: TOON 90.9% / JSON compact 90.9% / JSON 89.0% / YAML 87.1% / XML 80.9% / CSV 89.0% (flat).
Grok 4 fast (non-reasoning): TOON 57.4% / JSON 55.5% / JSON compact 54.5% / YAML 53.6% / XML 52.6% / CSV 52.3% (flat).
According to these results, TOON is equal to or better than JSON in accuracy across the models tested.
Mixed structure: where TOON helps
In the mixed structure track, token totals across the suite:
| Format | Tokens | Delta vs TOON |
|---|---|---|
| TOON | 226,613 | , |
| JSON | 289,901 | +21.8% |
| JSON compact | 197,270 | -14.9% |
| YAML | 239,958 | +5.6% |
| XML | 328,191 | +31.0% |
So in mixed structure datasets: TOON uses fewer tokens than formatted JSON, YAML, and XML. JSON compact uses fewer tokens than TOON, but TOON has higher accuracy per 1,000 tokens than JSON compact.
Flat-only: CSV vs TOON
In flat datasets, CSV is included. As expected, CSV is the most compact, with TOON slightly larger and JSON variants larger again.
Total for flat-only:
| Format | Tokens |
|---|---|
| CSV | 63,855 |
| TOON | 67,696 (+6.0% vs CSV) |
| JSON compact | 104,527 |
| YAML | 130,698 |
| JSON | 164,255 |
| XML | 190,160 |
This aligns with the documentation: CSV is smaller in flat tables, TOON is slightly larger but adds structure and guardrails that can help LLM reliability.
How I see it right now
I use JSON extensively across my current workflows for LLMs. It is the default structure for input and output, and it integrates cleanly with APIs, storage, and logging.
TOON is interesting because:
- It is designed for the LLM boundary, not for general APIs.
- It aims to be a lossless representation of JSON for model input.
- The published benchmarks show higher accuracy and better accuracy per token than JSON on the datasets tested.
- It performs particularly well when the data has a uniform or semi-uniform shape.
At the same time:
- JSON compact is still strong in non-tabular or deeply nested cases.
- CSV remains the smallest format for purely flat tables.
- TOON adds a format to learn and tooling to adopt.
My position is simple: JSON remains my default. I am testing TOON where the dataset is large, has a meaningful tabular structure, and I want to push more data into the context window without diluting signal. The published benchmarks justify that experiment. Whether TOON becomes a standard part of my stack will depend on how it performs in real workloads, not just synthetic tests.